
It is time to devalue the software research of climate models
When the table of contents of the most recent issue of the American Geophysical Union’s (AGU) Geophysical Research Letters was released on August 16, 2023, I could not help noticing it contained a string of papers repeatedly showing that the models used to prove the coming fire of global warming continue to remain untrustworthy and unreliable. All of the following papers indicated biases and uncertainties of both climate models as well as the data they used, and each did so in their titles:
- Climate Models Underestimate Dynamic Cloud Feedbacks in the Tropics
- Most Global Gauging Stations Present Biased Estimations of Total Catchment Discharge
- Different Methods in Assessing El Niño Flavors Lead to Opposite Results
- Biases in Estimating Long-Term Recurrence Intervals of Extreme Events Due To Regionalized Sampling
- A Pacific Tropical Decadal Variability Challenge for Climate Models
- Implications of Warm Pool Bias in CMIP6 Models on the Northern Hemisphere Wintertime Subtropical Jet and Precipitation
All of these papers considered the models valid for future research, and were instead focused on refining and increasing the accuracy of the models. All however showed once again how little we should trust these models.
What makes the publication of these papers significant is that it was the AGU that published them, even though the AGU has a decidedly biased editorial policy in favor of global warming. Despite the AGU’s insistence that “realistic and continually improving computer simulations of the global climate predict that global temperatures will continue to rise as a result of past and future greenhouse gas emissions,” it still cannot avoid publishing papers that repeatedly disprove that conclusion.
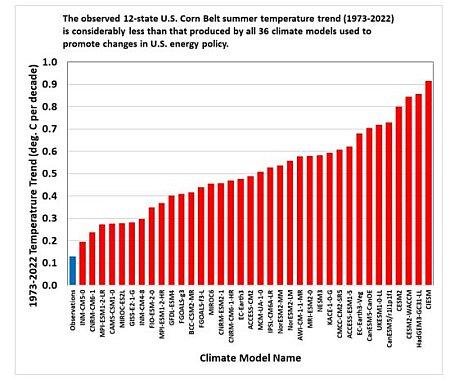
The science of modeling the climate, and using those models to predict global warming, is still quite unsettled and not to be trusted. As has been noted over and over again by honest scientists, none of these so-called “continually improving computer simulations” has ever successfully predicted anything, as indicated so eloquently by the graph to the right, published by climate scientist Roy Spencer in June. All thirty-six of the most trusted climate models failed to predict the actual temperature change from 1973 to 2022, with most failing quite badly.
More to the point is the greater problem caused by journals like the AGU giving the analysis of these models equal billing with research papers dealing with actual data. While computer models have some value in helping climate scientists understand how the climate functions, the models are not research. Each is simply a computer programmer’s attempt to create a model that simulates the atmosphere. The data in these models is by nature incomplete and often reduced significantly in resolution in order to allow the simulations to work within limited computer capabilities. And as the graph shows, as tools to predict the future they remain only slightly more useful than astrology.
By giving these papers the same exposure as research that describes the acquisition of actual climate data devalues that actual data, and makes it appear as if the computer models are real research as well.
Would it not make more sense to limit the publication of any climate model papers to their own journal, in order to emphasize their uncertainty and less-than-real nature? Putting them instead in their own less prominent publication would do nothing to stop this software research, but lower its status in the eyes of the public and other scientists. It would place it in its proper place: of some use but of a very limited kind.
Sadly, I do not expect the AGU, or any major science journal today, such as Science or Nature, to do this, because all have been captured and are controlled by global warming activists, who work hard to squelch any debate or dissent from their positions. Giving the climate models an overstated status helps that cause, even if it distorts science, making objective analysis of the data more difficult.
I make this suggestion simply to emphasize the difference between real research and playing with computer models, in the hope that other journalists as well as the public will begin to see this distinction as well. It is certainly long past time for journalists to stop reporting every prediction made by these models as gospel requiring big headlines. The reality is that the predictions are not much better than throwing darts at a wall, sometimes with blindfolds on.

On Christmas Eve 1968 three Americans became the first humans to visit another world. What they did to celebrate was unexpected and profound, and will be remembered throughout all human history. Genesis: the Story of Apollo 8, Robert Zimmerman's classic history of humanity's first journey to another world, tells that story, and it is now available as both an ebook and an audiobook, both with a foreword by Valerie Anders and a new introduction by Robert Zimmerman.
The print edition can be purchased at Amazon or from any other book seller. If you want an autographed copy the price is $60 for the hardback and $45 for the paperback, plus $8 shipping for each. Go here for purchasing details. The ebook is available everywhere for $5.99 (before discount) at amazon, or direct from my ebook publisher, ebookit. If you buy it from ebookit you don't support the big tech companies and the author gets a bigger cut much sooner.
The audiobook is also available at all these vendors, and is also free with a 30-day trial membership to Audible.
"Not simply about one mission, [Genesis] is also the history of America's quest for the moon... Zimmerman has done a masterful job of tying disparate events together into a solid account of one of America's greatest human triumphs."--San Antonio Express-News
For an excellent illustration of this “Model” problem I highly recommend the video linked below by Pat Frank, a Stanford researcher with a PhD in chemistry. In it he analyzes the error propagation implications for just 1 variable universally used in climate models (cloud feedback) to show how these models make predictions that are simply swamped by statistical error that cascades through the calculations from beginning to end.
I worked in the semiconductor world for over 25 years where physical modeling has been an invaluable tool to advancing the state of the art. And I can say with assurance that anyone submitting findings with such a shoddy methodology as illustrated here would have been unceremoniously fired for incompetence.
Math and statistics are mature sciences that demand you base precise conclusions on data that is itself precise, and when that is not the case you are compelled to document a rigorous characterization of the computational error so that you can judge the utility of the findings. This is completely absent in the field of climate modeling and these models should have been laughed off the stage decades ago.
For sure China and India understand this with their millions of newly minted engineering graduates each year who have learned how real science is done. And that is why they blithely ignore all the climate mongering and let the Bachelor of Art idiots of the West commit economic suicide based upon their climate horror fiction.
Very sad.
https://m.youtube.com/watch?v=THg6vGGRpvA&pp=ygURIm5vIGNlcnRhaW4gZG9vbSI%3D
As it happens, Sarah, I wrote a book on this published recently, refused by Amazon. The book is The Plague of Models, by Kenneth P. Green, and it’s available on Google Play Books, and in paperback through Barnes and Nobel. I’d love to get through to Glenn Reynolds to get a mention for it, as I believe that he’d agree strongly with it, but I’m not among the Instapundit Inside Cadre…
I posted this to InstaPundit’s comments on your post there, but wasn’t sure if you’d see that.
I believe that grants and funding as well as tenure is governed more by woke entities and ideologies than science.
It is impossible, for me as a layman, to ignore the results of all the models shown are increases in temperatures. If the “models” were unbiased, there would be some to show temperature declines. I don’t pretend to know how the author of the noted paper choose the models…but it is hard not to conclude that in a researcher’s mind when he has to use a parameter to modify the data, the one that is more likely to increase a temperature or lower it, the former is always chosen.
Kenneth P. Green: Thank you for the comment. Note that Sarah Hoyt did not write this essay. I did.
Gina Marie Wylie: 1. Roy Spencer, who created that graph, is a long time climate scientist who has also been the principle investigator on at least one important climate satellite (maybe more, I don’t remeber for sure). He knows his stuff, and is also unwavering in his loyalty to truth and data, not agenda or theory.
2. See these posts:
There are many more on this site, but many are old, because by 2019 I had become completely bored with reporting what was obvious, that the government scientists in charge of the global climate data sets were clearly fudging the data to cool older numbers so that the present seemed hotter. And they were doing it without providing any convincing explanation for the changes.
The failure of the models is simply another illustration of the confirmation bias that now dominates climate science. Getting the facts — no matter where they lead — is no longer the goal. The goal is instead shaping the facts to prove the theory of human-caused global warming, even if the facts say it is wrong.
I am NOT a scientist. I am, however, a software engineer with over 30 years’ experience, and have been called a good one.
I went through a lit of the original Climategate emails in the early-to-mid 2000s, ind tucked in there was some source code for 1 or 2 of their “models”. I don’t remember even what language they were in, except that it was not one of my primary languages (but easy enough to read).
It was FILLED with what we call “magic numbers”. This essentially means 2 different things, depending on context, and both were ubiquitous. One, less important but indicative, was that they arbitrarily assigned numbers to mean things, and didn’t bother with essentially ANY decent pnemonics or anything else to make their code more readable. That is some sloppy, unprofessional [deleted] right there. Two, at several points they would simply add, subtract, multiply or divide a seemingly random hard coded number into what looked like important calculations. No explanation. Uncommented code.
That was when I formed my opinion that the entire climate enterprise was a scam, and not even a clever one. Every dollar ever spent on it is utterly wasted, if the goal is properly to “fix” the climate. That code looked like its author had less than 2 years of programming behind them, and they were probably handed “adjustments” to plug in without even knowing what they were or why. It looked like a transparent exercise in goal-seeking.
When they make these models open source, as they should have been from day one if this was a real problem that needed solving for the good of mankind, then I may take another look and start pointing the problems out to those yahoo’s. Until then, I am blissfully happy every time a multi-billion-dollar climate boondoggle bill is blocked, and you should be too, and vote accordingly.
What do people think about this from a physics person who is explaining things on terms of radiative transport. From 6 months ago and she references a book. Of course no complex modeling or clouds. https://youtu.be/oqu5DjzOBF8
Bad sign to do a double post, but I do think the radiative transport presented was over simplified. The video also mentions the 2021 Nobel prize in physics https://www.nobelprize.org/all-nobel-prizes-2021/
It still comes down to the modeling.
Dan: You should read the rules. I do not allow obscenities. Your comment went into moderation because you used one. I have deleted it and approved your comment, but next time I will not do so, and will suspend you for a week.
Why is it people now consider it cool to debase themselves in this way? You sound like an intelligent, civilized person. No need to make yourself look bad for no reason. But you do.
Heh. When I read the comment I wondered if the “[deleted]” was Dan or Robert. Now I know.
Hockey stick graphs from the hockey pucks.
As people have noted in these comments, models are difficult to create accurately and to use properly. In this case, the errors build up fast, because the data that they use to create the models and the information that pops out of them are not just full of error bars, but the models are not based upon actual data that has been collected from the real world. They are based upon datasets of annual average temperatures and other averages (e.g. rainfall, hurricanes, etc.). These averages are not real data points but are processed data. The base data points, the real world recorded temperatures, have small error bars that are not well recognized in the processed data. The real data points are processed into daily global averages, which have their own error bars, then they are further processed into annual global averages, with their own error bars. These annual global averages are then used to create models, which begin with error bars that make the models difficult to make so that they can predict the future — the purpose of any model.
These scientists may be over-certain about the results that they get from their models.
Virtually everything we do is based upon predictions of the future, from predictions of weather in order to grow crops and livestock, to predictions of travel in order to fly aircraft across mountain ranges and oceans without running out of fuel. We choose bedtimes on predictions of when we will wake up to start the next day. All these predictions are based upon models, even the last one, in which the model is in our heads and based upon perceived previous experiences rather than data collected, collated, processed, and analyzed for accurate prediction skills.
One would think that a species that is so good at making individual models so that we can predict how much we will eat tonight so that we can cook enough but not cook too much for dinner, we would have some ability to create more complex models, and that we would spend a lot of resources correcting the models that are about to suggest how to direct trillions of dollars of resources in order to stop or redirect the Earth’s naturally changing climates. If these models are not skilled at predicting the future, why would anyone be stupid enough to rely upon them to determine the expenditure of so many resources?
One of the disturbing things about these models was their complete failure to predict the temperature “pause” that began late in the 1990s. More disturbing is the people who are tasked with keeping the datasets used for climate analyses and for model generation. When the models failed to predict the “pause,” these people were willing to modify the datasets in order to better match the trends predicted by the models rather than insist that the models be modified in such ways that their future predictions will better match reality.
But most disturbing of all is that the rest of the scientific community failed to call out the fudging of our historical climate datasets. All future climate science has been corrupted by the corruption of these datasets. No future models and no climate predictions at all can ever be trusted, because they are based upon fudged information and must necessarily give phony results.
This is the tragedy of fudged data and of confirmation bias. Reality is secondary to these people, but reality is where the rest of us live our daily lives, and we depend upon real predictions to make sure that we don’t sail into arctic ice flows, try to grow crops when the weather will not be right, or create a society of lives and livelihoods that are dependent upon more electricity than the government allows to be produced. It doesn’t matter whether we produce enough food if the electric trucks cannot deliver it to the hungry population.
Professor William Happer IPA lecture – The Crusade Against Carbon Dioxide – September 2023
In September 2023, Princeton University’s Emeritus Cyrus Fogg Brackett Professor of Physics, William Happer, spoke to an audience in Brisbane, Australia about the crusade against carbon dioxide and integrity in climate science.
Professor Happer is one of the world’s leading scientists and climate realists, having made extensive contributions to the debate about climate science. He has played a vital role in ensuring there is integrity in climate science and the community is exposed to information and arguments that many major institutions in our society seek to silence or censor.
The Institute of Public Affairs was proud to host Professor Happer on a tour around Australian where he spoke to audiences in Perth, Melbourne, Sydney and Brisbane.
https://www.youtube.com/watch?v=v2nhssPW77I